Timothée Chalamet, Charli XCX and Billie Eilish are among those who trust Aidan Zamiri, a director and photographer, with their images.


|
Pragmatic idealist. Worked on Ubuntu Phone. Inkscape co-founder. Probably human.
|


In February 1982, Apple employee #8 Chris Espinosa faced a problem that would feel familiar to anyone who has ever had a micromanaging boss: Steve Jobs wouldn’t stop critiquing his calculator design for the Mac. After days of revision cycles, the 21-year-old programmer found an elegant solution: He built what he called the “Steve Jobs Roll Your Own Calculator Construction Set” and let Jobs design it himself.
This delightful true story comes from Andy Hertzfeld’s Folklore.org, a legendary tech history site that chronicles the development of the original Macintosh, which was released in January 1984. I ran across the story again recently and thought it was worth sharing as a fun anecdote in an age where influential software designs often come by committee.
Chris Espinosa started working for Apple at age 14 in 1976 as the company’s youngest employee. By 1981, while studying at UC Berkeley, Jobs convinced Espinosa to drop out and work on the Mac team full time.
Believe it or not, Chris Espinosa still works at Apple as its longest-serving employee. But back in the day, as manager of documentation for the Macintosh, Espinosa decided to write a demo program using Bill Atkinson’s QuickDraw, the Mac’s graphics system, to better understand how it worked. He chose to create a calculator as one of the planned “desk ornaments,” which were small utility programs that would ship with the Mac. They later came to be called “desk accessories.”
Espinosa thought his initial calculator design looked good, but Jobs had other ideas when he saw it. Hertzfeld describes the scene: “Well, it’s a start,” Steve said, “but basically, it stinks. The background color is too dark, some lines are the wrong thickness, and the buttons are too big.”
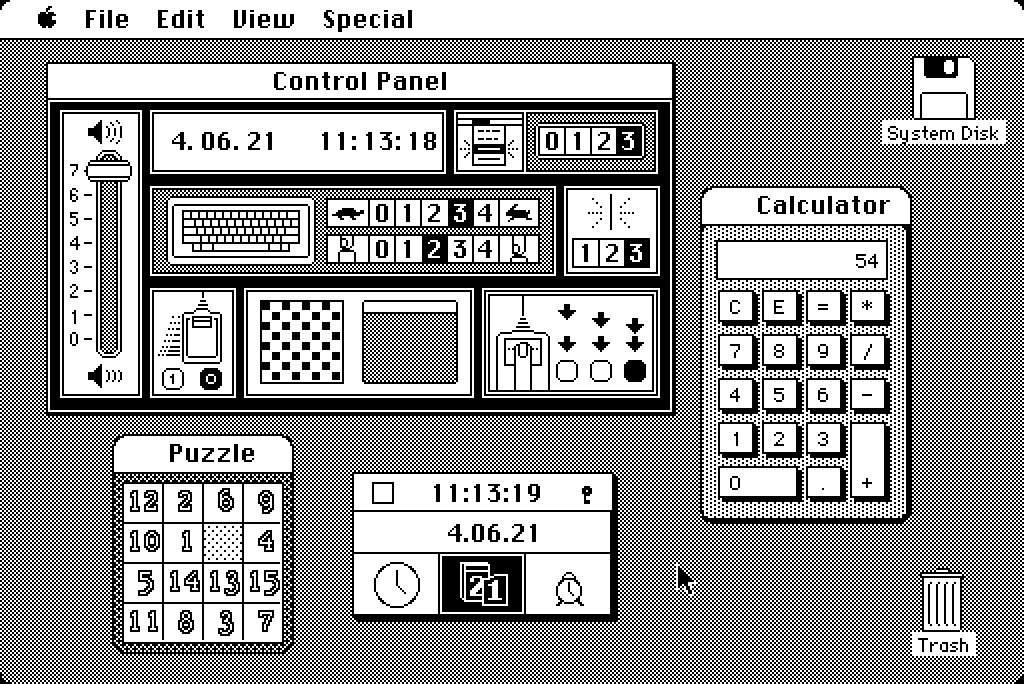 The Mac OS 1.0 calculator seen in situ with other desk accessories.
Credit:
Apple / Benj Edwards
The Mac OS 1.0 calculator seen in situ with other desk accessories.
Credit:
Apple / Benj Edwards
For several days, Espinosa would incorporate Jobs’s suggestions from the previous day, only to have Jobs find new faults with each iteration. It might have felt like a classic case of “design by committee,” but in this case, the committee was just one very particular person who seemed impossible to satisfy.
Rather than continue the endless revision cycle, Espinosa took a different approach. According to Hertzfeld, Espinosa created a program that exposed every visual parameter of the calculator through pull-down menus: line thickness, button sizes, background patterns, and more. When Jobs sat down with it, he spent about ten minutes adjusting settings until he found a combination he liked.
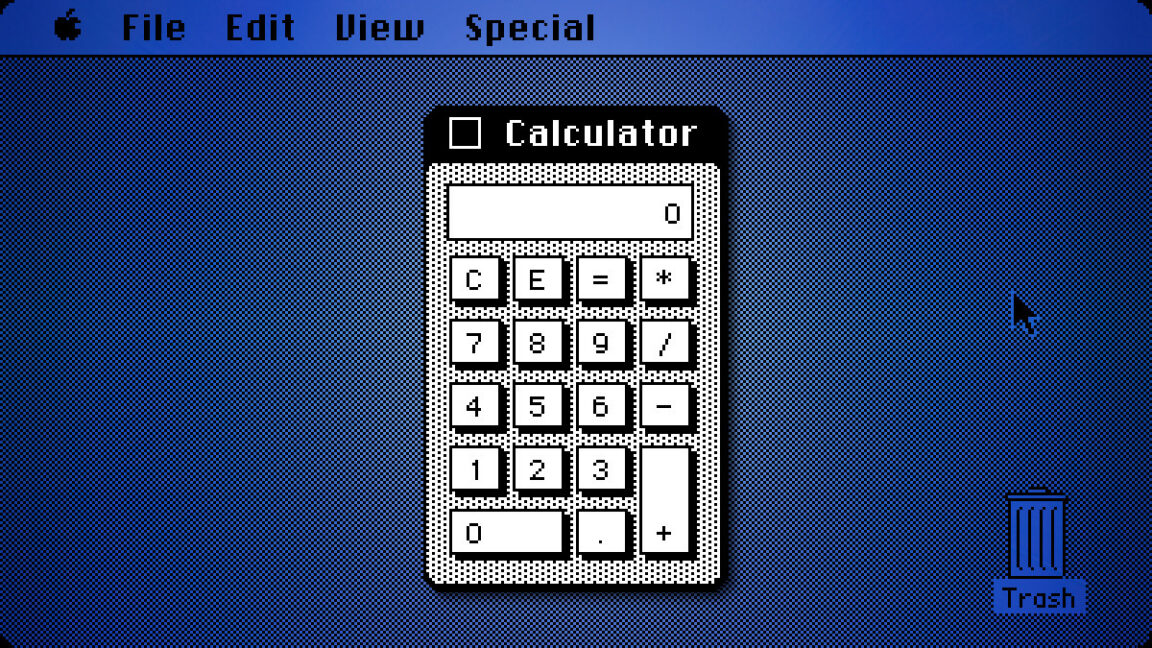
The approach worked. When given direct control over the parameters rather than having to articulate his preferences verbally, Jobs quickly arrived at a design he was satisfied with. Hertzfeld notes that he implemented the calculator’s UI a few months later using Jobs’s parameter choices from that ten-minute session, while Donn Denman, another member of the Macintosh team, handled the mathematical functions.
That ten-minute session produced the calculator design that shipped with the Mac in 1984 and remained virtually unchanged through Mac OS 9, when Apple discontinued that OS in 2001. Apple replaced it in Mac OS X with a new design, ending the calculator’s 17-year run as the primary calculator interface for the Mac.
Espinosa’s Construction Set was an early example of what would later become common in software development: visual and parameterized design tools. In 1982, when most computers displayed monochrome text, the idea of letting someone fine-tune visual parameters through interactive controls without programming was fairly forward-thinking. Later, tools like HyperCard would formalize this kind of idea into a complete visual application framework.
The primitive calculator design tool also revealed something about Jobs’s management process. He knew what he wanted when he saw it, but he perhaps struggled to articulate it at times. By giving him direct manipulation ability, Espinosa did an end-run around that communication problem entirely. Later on, when he returned to Apple in the late 1990s, Jobs would famously insist on judging products by using them directly rather than through canned PowerPoint demos or lists of specifications.
The longevity of Jobs’s ten-minute design session suggests the approach worked. The calculator survived nearly two decades of Mac OS updates, outlasting many more elaborate interface elements. What started as a workaround became one of the Mac’s most simple but enduring designs.
By the way, if you want to try the original Mac OS calculator yourself, you can run various antique versions of the operating system in your browser thanks to the Infinite Mac website.
The decisions by major AI companies—xAI in July, Meta in August, and OpenAI last month—to open their chatbots to erotica have supercharged debate around humans forming romantic relationships with AI. Critics argue that this is the end of human connection.
I founded and run one of the largest romantic chat companies in the world, janitorAI. And yes, I chat with the bots myself—mafiosa Nova Marino is a personal favorite. When I launched the site in 2023, OpenAI sent me a cease-and-desist order because our users were using our platform together with OpenAI’s model to generate romantic content. Our website couldn’t access OpenAI’s application programming interface, and the company disabled some of our users’ OpenAI accounts for violating its terms of service. A few months later, that ban quietly disappeared.
When engineers build AI language models like GPT-5 from training data, at least two major processing features emerge: memorization (reciting exact text they’ve seen before, like famous quotes or passages from books) and reasoning (solving new problems using general principles). New research from AI startup Goodfire.ai provides the first potentially clear evidence that these different functions actually work through completely separate neural pathways in the model’s architecture.
The researchers discovered that this separation proves remarkably clean. In a preprint paper released in late October, they described that when they removed the memorization pathways, models lost 97 percent of their ability to recite training data verbatim but kept nearly all their “logical reasoning” ability intact.
For example, at layer 22 in Allen Institute for AI’s OLMo-7B language model, the bottom 50 percent of weight components showed 23 percent higher activation on memorized data, while the top 10 percent showed 26 percent higher activation on general, non-memorized text. This mechanistic split enabled the researchers to surgically remove memorization while preserving other capabilities.
Perhaps most surprisingly, the researchers found that arithmetic operations seem to share the same neural pathways as memorization rather than logical reasoning. When they removed memorization circuits, mathematical performance plummeted to 66 percent while logical tasks remained nearly untouched. This discovery may explain why AI language models notoriously struggle with math without the use of external tools. They’re attempting to recall arithmetic from a limited memorization table rather than computing it, like a student who memorized times tables but never learned how multiplication works. The finding suggests that at current scales, language models treat “2+2=4” more like a memorized fact than a logical operation.
It’s worth noting that “reasoning” in AI research covers a spectrum of abilities that don’t necessarily match what we might call reasoning in humans. The logical reasoning that survived memory removal in this latest research includes tasks like evaluating true/false statements and following if-then rules, which are essentially applying learned patterns to new inputs. This also differs from the deeper “mathematical reasoning” required for proofs or novel problem-solving, which current AI models struggle with even when their pattern-matching abilities remain intact.
Looking ahead, if the information removal techniques receive further development in the future, AI companies could potentially one day remove, say, copyrighted content, private information, or harmful memorized text from a neural network without destroying the model’s ability to perform transformative tasks. However, since neural networks store information in distributed ways that are still not completely understood, for the time being, the researchers say their method “cannot guarantee complete elimination of sensitive information.” These are early steps in a new research direction for AI.
To understand how researchers from Goodfire distinguished memorization from reasoning in these neural networks, it helps to know about a concept in AI called the “loss landscape.” The “loss landscape” is a way of visualizing how wrong or right an AI model’s predictions are as you adjust its internal settings (which are called “weights”).
Imagine you’re tuning a complex machine with millions of dials. The “loss” measures the number of mistakes the machine makes. High loss means many errors, low loss means few errors. The “landscape” is what you’d see if you could map out the error rate for every possible combination of dial settings.
During training, AI models essentially “roll downhill” in this landscape (gradient descent), adjusting their weights to find the valleys where they make the fewest mistakes. This process provides AI model outputs, like answers to questions.
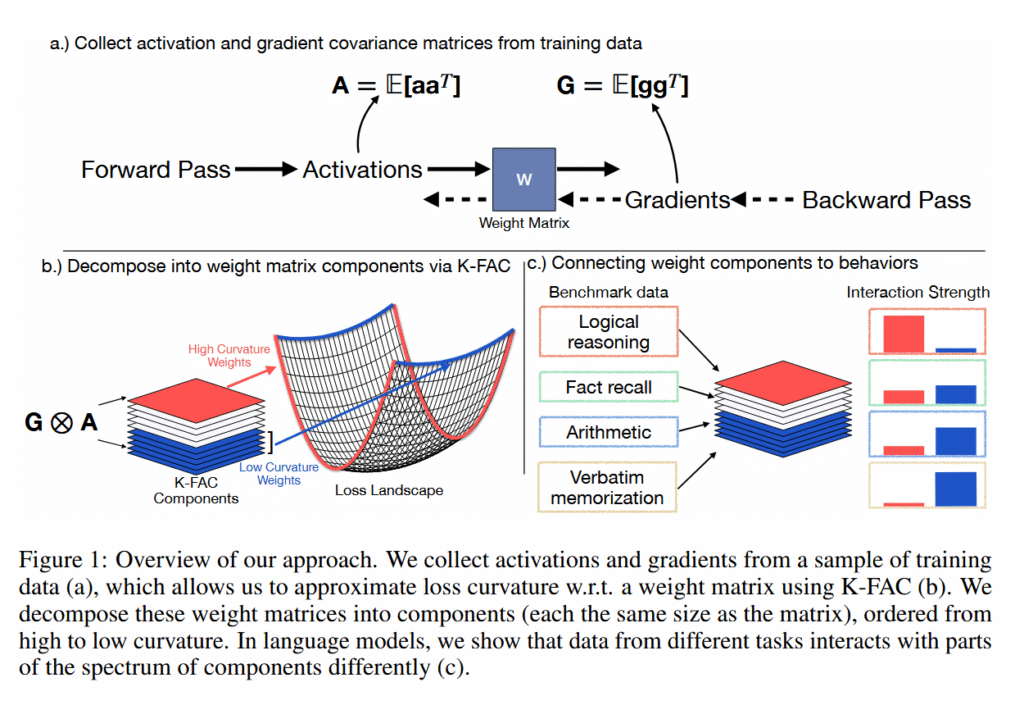 Figure 1 from the paper “From Memorization to Reasoning in the Spectrum of Loss Curvature.”
Credit:
Merullo et al.
Figure 1 from the paper “From Memorization to Reasoning in the Spectrum of Loss Curvature.”
Credit:
Merullo et al.
The researchers analyzed the “curvature” of the loss landscapes of particular AI language models, measuring how sensitive the model’s performance is to small changes in different neural network weights. Sharp peaks and valleys represent high curvature (where tiny changes cause big effects), while flat plains represent low curvature (where changes have minimal impact).
Using a technique called K-FAC (Kronecker-Factored Approximate Curvature), they found that individual memorized facts create sharp spikes in this landscape, but because each memorized item spikes in a different direction, when averaged together they create a flat profile. Meanwhile, reasoning abilities that many different inputs rely on maintain consistent moderate curves across the landscape, like rolling hills that remain roughly the same shape regardless of the direction from which you approach them.
“Directions that implement shared mechanisms used by many inputs add coherently and remain high-curvature on average,” the researchers write, describing reasoning pathways. In contrast, memorization uses “idiosyncratic sharp directions associated with specific examples” that appear flat when averaged across data.
The researchers tested their technique on multiple AI systems to verify the findings held across different architectures. They primarily used Allen Institute’s OLMo-2 family of open language models, specifically the 7 billion- and 1 billion-parameter versions, chosen because their training data is openly accessible. For vision models, they trained custom 86 million-parameter Vision Transformers (ViT-Base models) on ImageNet with intentionally mislabeled data to create controlled memorization. They also validated their findings against existing memorization removal methods like BalancedSubnet to establish performance benchmarks.
The team tested their discovery by selectively removing low-curvature weight components from these trained models. Memorized content dropped to 3.4 percent recall from nearly 100 percent. Meanwhile, logical reasoning tasks maintained 95 to 106 percent of baseline performance.
These logical tasks included Boolean expression evaluation, logical deduction puzzles where solvers must track relationships like “if A is taller than B,” object tracking through multiple swaps, and benchmarks like BoolQ for yes/no reasoning, Winogrande for common sense inference, and OpenBookQA for science questions requiring reasoning from provided facts. Some tasks fell between these extremes, revealing a spectrum of mechanisms.
Mathematical operations and closed-book fact retrieval shared pathways with memorization, dropping to 66 to 86 percent performance after editing. The researchers found arithmetic particularly brittle. Even when models generated identical reasoning chains, they failed at the calculation step after low-curvature components were removed.
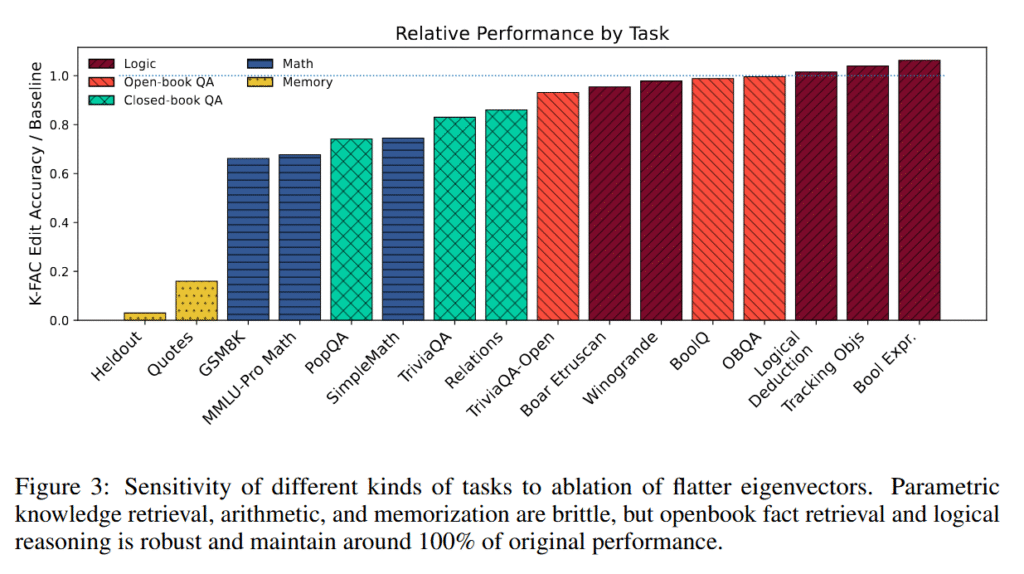 Figure 3 from the paper “From Memorization to Reasoning in the Spectrum of Loss Curvature.”
Credit:
Merullo et al.
Figure 3 from the paper “From Memorization to Reasoning in the Spectrum of Loss Curvature.”
Credit:
Merullo et al.
“Arithmetic problems themselves are memorized at the 7B scale, or because they require narrowly used directions to do precise calculations,” the team explains. Open-book question answering, which relies on provided context rather than internal knowledge, proved most robust to the editing procedure, maintaining nearly full performance.
Curiously, the mechanism separation varied by information type. Common facts like country capitals barely changed after editing, while rare facts like company CEOs dropped 78 percent. This suggests models allocate distinct neural resources based on how frequently information appears in training.
The K-FAC technique outperformed existing memorization removal methods without needing training examples of memorized content. On unseen historical quotes, K-FAC achieved 16.1 percent memorization versus 60 percent for the previous best method, BalancedSubnet.
Vision transformers showed similar patterns. When trained with intentionally mislabeled images, the models developed distinct pathways for memorizing wrong labels versus learning correct patterns. Removing memorization pathways restored 66.5 percent accuracy on previously mislabeled images.
However, the researchers acknowledged that their technique isn’t perfect. Once-removed memories might return if the model receives more training, as other research has shown that current unlearning methods only suppress information rather than completely erasing it from the neural network’s weights. That means the “forgotten” content can be reactivated with just a few training steps targeting those suppressed areas.
The researchers also can’t fully explain why some abilities, like math, break so easily when memorization is removed. It’s unclear whether the model actually memorized all its arithmetic or whether math just happens to use similar neural circuits as memorization. Additionally, some sophisticated capabilities might look like memorization to their detection method, even when they’re actually complex reasoning patterns. Finally, the mathematical tools they use to measure the model’s “landscape” can become unreliable at the extremes, though this doesn’t affect the actual editing process.

Formula E officially revealed its next electric racing car today. At first glance, the Gen4 machine looks similar to machinery of seasons past, but looks are deceiving—it’s “so much more menacing,” according to Formula E CEO Jeff Dodds. The new car is not only longer and wider, it’s far more powerful. The wings and bodywork now generate meaningful aerodynamic downforce. There will be a new tire supplier as Bridgestone returns to single-seat racing. The car is even completely recyclable.
I’m not sure that everyone who attended a Formula E race in its first season would have bet on the sport’s continued existence more than a decade down the line. When the cars took their green flag for the first time in Beijing in 2014, as many people derided it for being too slow or for the mid-race car swaps as praised it for trying something new in the world of motorsport.
Despite that, the racing was mostly entertaining, and it got better with the introduction of the Gen2 car, which made car swapping a thing of the past. Gen3 added more power, then temporary all-wheel drive with the advent of the Gen3 Evo days. That car will continue to race in season 12, which kicks off in Brazil on December 6 and ends in mid-August in London. When season 13 picks up in late 2026, we might see a pretty different kind of Formula E racing.
 The HALO head protection will be more necessary than ever, given the higher speeds of the new car.
Credit:
Formula E
The HALO head protection will be more necessary than ever, given the higher speeds of the new car.
Credit:
Formula E
“It feels like a real moment for us,” said Dodds. The new car will generate 603 hp in race mode, a 50 percent jump compared to the Gen3 Evo. That goes up to 804 hp (600 kW) in attack mode. For context, next year’s F1 cars will generate more power, but only when their batteries are fully charged; if the battery is depleted, that leaves just a 536 hp (400 kW) V6.
Acceleration should be extremely violent thanks to permanent AWD—the first for any single seater in FIA competition, at least for the last few decades. Top speed will be close to double that of the original race car, topping out at 210 mph (337 km/h). Now you can see why the sport decided that aerodynamic grip would be a useful addition.
In fact, there will be two different bodywork configurations, one for high downforce and the other with less. But that doesn’t mean Formula E teams will run out and build wind tunnels, like their F1 counterparts. “There’s significant gains that can be made out of software improvements, efficiency improvements, powertrain developments,” said Dodds, so there’s no incentive to spend lots of money on aero development that would only add fractions of a second.
The biggest opportunity for finding performance improvements may be with traction control and antilock braking systems. Formula E wants its technology to be road-relevant, so such driver aids will be unlimited in the Gen4 era. But efficiency will remain of utmost importance; the cars will still have to regenerate 40 percent of the energy they need to finish the race, as the 55 kWh battery is not sufficient to go flat-out to the end. Happily for the drivers, the new car can regen up to 700 kW of energy under braking.
 The Gen4 car in testing.
Credit:
Formula E
The Gen4 car in testing.
Credit:
Formula E
Finally, the car’s end of life has been considered. The entire race car is entirely recyclable, Formula E says, and it already contains 20 percent recycled content.
So far, the Gen4 car has been put through its paces for more than 5,000 miles (8,000 km), which is more than the mileage of an entire Formula E season, including testing. Now the teams have started to receive their chassis and have started the work of getting to know them and preparing to race them in season 13, all while getting ready to start season 12 next month.
What we won’t know until season 13 gets underway is how the Gen4 era will change the races. With bigger, faster cars, not every Formula E circuit will still be suitable, like London’s very tight Excel Arena track, but with a continued focus on making efficiency count, it’s quite likely we’ll continue to see the same close pack racing as before.
